|
|
 发表于 2022-11-27 13:45:57
|
显示全部楼层
发表于 2022-11-27 13:45:57
|
显示全部楼层
作者:善思者_tin
链接:https://www.jianshu.com/p/c2c081b51ab9
一、概述
顺势而为,大数据高并发要有系统不断的升级,分库分表便是其一。
二、为什么要分库分表
场景:随着互联网技术的蓬勃发展,大数据,高并发是很多公司遇到的情况。比如公司业务的发展,系统用户量迅速增加,系统每天会多 10 万条数据,一个月就多 300 万条数据,单表已经会达到几百万数据量,高峰期请求达到 1000。处理方式是我们在线上部署了几台机器,通过nginx做负载均衡,数据库撑 1000QPS 也还将就。然而,数据量不断在增长,接下来该如何处理呢?
当每天活跃用户数上千万,每天单表新增数据多达 50 万,目前一个表总数据量都已经达到了两三千万了,数据库磁盘容量不断消耗掉,高峰期并发达到惊人的 5000~8000QPS!此时,单个数据库已经抗不住了。
三、分表
3.1、分表的方案
当单表达到几千万的时候,单表数据量太大,会极大影响 sql 执行的性能,到了后面你的 sql 可能就跑的很慢了。一般来说,单表到几百万的时候,性能就会相对差一些了,就得分表了。
根据数值取模
采用Id取模的方式来进行分表。比如那customer表举例,将customer 表根据 cusno 字段切分到4个库中,余数为0的放到第一个库,余数为1的放到第二个库,余数为2的放到第三个库,余数为3的放到第三个库。这样同一个用户的数据会分散到不同的表中,如果查询条件带有cusno字段,则可明确定位到相应表去查询。
实例说明:
首先创建三张表 customer0/ customer1/customer2/customer3, 然后我再创建 uuid表,该表的作用就是提供自增的id。
createtable**customer0**(idintunsignedprimarykey,namevarchar(32)notnulldefault'',pwdvarchar(32)notnulldefault'')engine=myisamcharsetutf8;createtable**customer1**(idintunsignedprimarykey,namevarchar(32)notnulldefault'',pwdvarchar(32)notnulldefault'')engine=myisamcharsetutf8;createtable**customer2**(idintunsignedprimarykey,namevarchar(32)notnulldefault'',pwdvarchar(32)notnulldefault'')engine=myisamcharsetutf8;createtable**customer3**(idintunsignedprimarykey,namevarchar(32)notnulldefault'',pwdvarchar(32)notnulldefault'')engine=myisamcharsetutf8;createtable**uuid**(idintunsignedprimarykeyauto_increment)engine=myisamcharsetutf8;**利用以上创建的表进行业务处理**@ServicepublicclassCustomerService{@AutowiredprivateJdbcTemplatejdbcTemplate;/***注册的代码*@paramname*@parampwd*@return*/publicStringregiter(Stringname,Stringpwd){//1.生成cusno,-先获取到自定增长IDStringinsertUUidSql="insertintouuidvalues(null)";//插入空数据,这里的id是自动增长的jdbcTemplate.update(insertUUidSql);//执行//查询到最近的添加的主键idLongcusno=jdbcTemplate.queryForObject("selectlast_insert_id()",Long.class);//2.存放具体的那张表中-也就是判断存储表名称StringtableName="customer"+cusno%3;//3.插入到具体的表中去-注册数据StringinsertUserSql="INSERTINTO"+tableName+"VALUES('"+cusno+"','"+name+"','"+pwd+"');";System.out.println("insertUserSql:"+insertUserSql);jdbcTemplate.update(insertUserSql);return"success";}/***通过cusno查询name*@paramuserid*@return*/publicStringget(Longcusno){//具体哪张表StringtableName="customer"+cusno%3;Stringsql="selectnamefrom"+tableName+"whereid="+cusno;System.out.println("SQL:"+sql);returnjdbcTemplate.queryForObject(sql,String.class);//执行查询出name}}优缺点总结
优点:
将一个数据表的数据分成多个表后,数据相对比较均匀,减轻来高并发访问带来的数据库压力。
缺点:
后期如果扩容时,需要迁移旧的数据重新计算。
跨分表查询复杂性增加。比如上例中,如果频繁用到的查询条件中不带cusno时,将会导致无法定位数据库,从而需要同时向4个库发起查询,再在内存中合并数据,取最小集返回给应用,分库反而成为拖累。
根据数值范围
为了解决后期集群扩容需要迁移旧数据的问题,可以使用按日期或者ID来进行分表。例如:按日期将不同月甚至是日的数据分散到不同的表中;将cusno为1~9999的记录分到第一个表,10000~20000的分到第二个表,以此类推。某种意义上,某些系统中使用的"冷热数据分离",将一些使用较少的历史数据迁移到其他库中,业务功能上只提供热点数据的查询,也是类似的实践。
优缺点
优点:
单表大小可控
天然便于水平扩展,后期如果想对整个分片集群扩容时,只需要添加节点即可,无需对其他分片的数据进行迁移
使用分片字段进行范围查找时,连续分片可快速定位分片进行快速查询,有效避免跨分片查询的问题。微信搜索公众号:Linux技术迷,回复:linux 领取资料 。
缺点:
热点数据成为性能瓶颈。连续分片可能存在数据热点,例如按时间字段分片,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询。
四、分库
就是你一个库一般最多支撑到并发 2000,随着查询量的增加单台数据库服务器已经没办法支撑,而且一个健康的单库并发值你最好保持在每秒 1000 左右,不要太大,太大会导致单台DB的存储空间不够。那么你就可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
垂直拆分
垂直拆分意思就是处理数据库的列,列和对应的业务有关系,意思就是就是根据业务耦合性,将关联度低的不同表存储在不同的数据库。
联想到微服务,做法与大系统拆分为多个小系统类似,按业务分类进行独立划分,每个微服务使用单独的一个数据库。比如最初就一个数据库为db_shop,db_shop库包含user,product表,随着公司业务的发展,技术团队人员也得到了扩张,划分为不同的技术小组,不同的小组负责不同的业务模块。例如A小组负责用户模块,B小组负责产品模块,拆分为db_user库和db_product库
需要解决的问题:跨数据库的事务、jion查询等问题。
水平拆分
按照规则划分,一般水平分库是在垂直分库之后的。比如每天处理的订单数量是海量的,可以按照一定的规则水平划分。比如某张表太大,单个数据库存储不下或访问性能有压力,把一张表拆成多张,每张表存放部分记录,保存在不同的数据库里,水平分库需要对系统做大的改造。
1)Scale up,升级数据库所在的物理机,提升内存/存储/IO性能,但这种升级费用昂贵,并且只能满足短期需要。
2)Scale out,把订单库拆分为多个库,分散到多台机器进行存储和访问,这种做法支持水平扩展,可以满足长远需要。
订单库主要包括订单主表/订单明细表(记录商品明细)/订单扩展表,水平分库即把这3张表的记录分到多个数据库中,订单水平分库效果如下图所示:
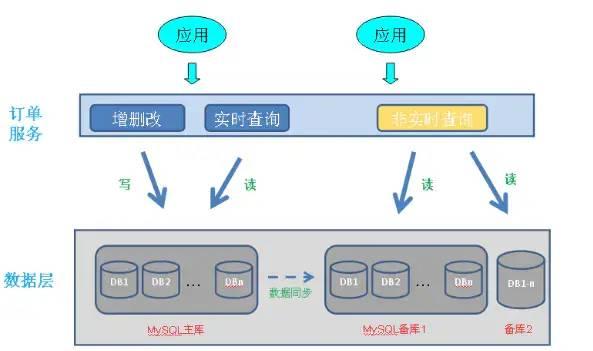
分库策略:和水平分表类似
分库维度确定后,如何把记录分到各个库里呢?一般有两种方式:
根据数值范围,比如用户Id为1-9999的记录分到第一个库,10000-20000的分到第二个库,以此类推。
根据数值取模,比如用户Id mod n,余数为0的记录放到第一个库,余数为1的放到第二个库,以此类推。
需要解决的问题:数据路由、组装。
读写分离
对于时效性不高的数据,可以通过读写分离缓解数据库压力。
需要解决的问题:在业务上区分哪些业务上是允许一定时间延迟的,以及数据同步问题。
垂直分库-->水平分库-->读写分离
五、拆分后面临新的问题的解决方案
常用的解决方案:站在巨人的肩膀上能省力很多,目前分库分表已经有一些较为成熟的开源解决方案。
选用第三方的数据库中间件(Atlas,Mycat,TDDL,DRDS),同时业务系统需要配合数据存储的升级。综合考虑,现在其实建议考量的,就是 Sharding-jdbc 和 Mycat,这两个都可以去考虑使用。
Sharding-jdbc 这种 client 层方案的优点在于不用部署,运维成本低,不需要代理层的二次转发请求,性能很高,但是如果遇到升级啥的需要各个系统都重新升级版本再发布,各个系统都需要耦合 Sharding-jdbc 的依赖;
Mycat 这种 proxy 层方案的缺点在于需要部署,自己运维一套中间件,运维成本高,但是好处在于对于各个项目是透明的,如果遇到升级之类的都是自己中间件那里搞就行了。
通常来说,这两个方案其实都可以选用,但是我个人建议中小型公司选用 Sharding-jdbc,client 层方案轻便,而且维护成本低,不需要额外增派人手,而且中小型公司系统复杂度会低一些,项目也没那么多;但是中大型公司最好还是选用 Mycat 这类 proxy 层方案,因为可能大公司系统和项目非常多,团队很大,人员充足,那么最好是专门弄个人来研究和维护 Mycat,然后大量项目直接透明使用即可。
附:
负载均衡:汽车超载,多台汽车运送物质。有个总调度中心,分配每辆车的权重,分别拉多少货物。在系统里面,这个总调度中心可以是nginx,通过配置多台服务器的ip,进行权重分配,使用轮询算法,实现应对并发量大的策略。
主键生成策略:

--完--读到这里说明你喜欢本公众号的文章,欢迎置顶(标星)本公众号架构师指南,这样就可以第一时间获取推送了~在本公众号架构师指南,后台回复:架构师,领取2T学习资料!推荐阅读1.后端架构师技术大全(69个点)2.架构师如何设计权限系统?3.我怎么才能成为一个架构师 ?4.架构师从0搭建一套订单系统! |
|

