在由腾讯游戏学堂举办的TGDC2022腾讯游戏开发者大会上,来自Epic Games China的技术支持工程师刘炜,就围绕这次虚幻引擎5下移动端延迟管线技术的更新做了一次技术层面的讲解。针对其与前向渲染相比的优点、GBuffer格式的布局、可能遇到的兼容性问题,以及虚幻5对比虚幻4而言新增的功能及其使用方式,带来一场细致入微的经验分享。
延迟渲染也没有占用更多的带宽,虽然延迟渲染需要创建多张GBuffer,但是我们可以利用Tiled Based GPU的特性,把GBuffer分配在Tiled Memory上,这样就不用存回System Memory,从而减少带宽占用。不过这样也会带来一个问题,就是无法在后期中访问GBuffer里的数据,这也是目前移动端不支持Screen Space Reflection的一个原因。
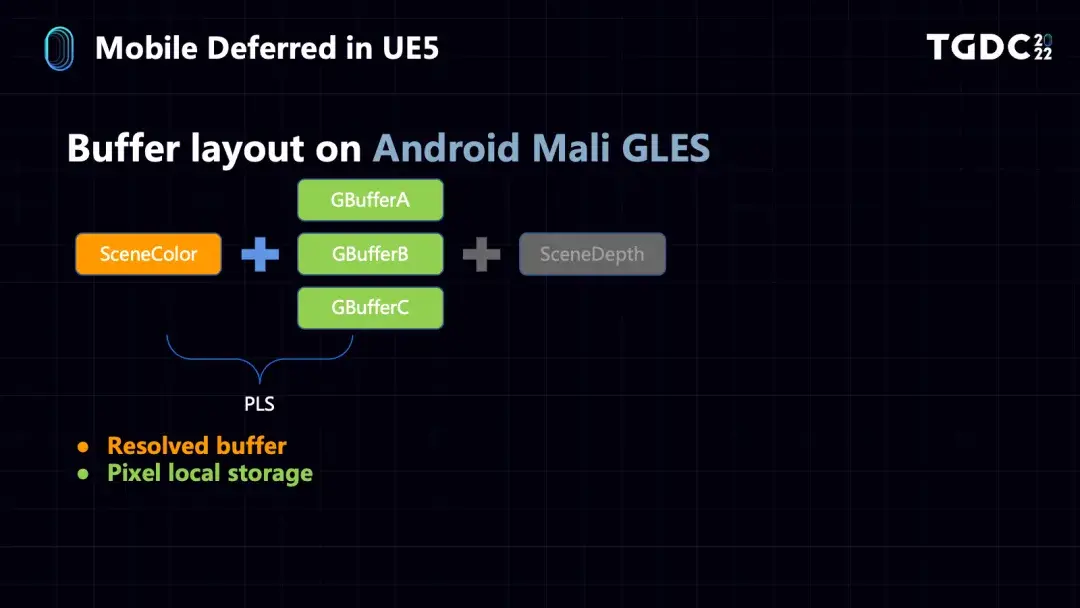
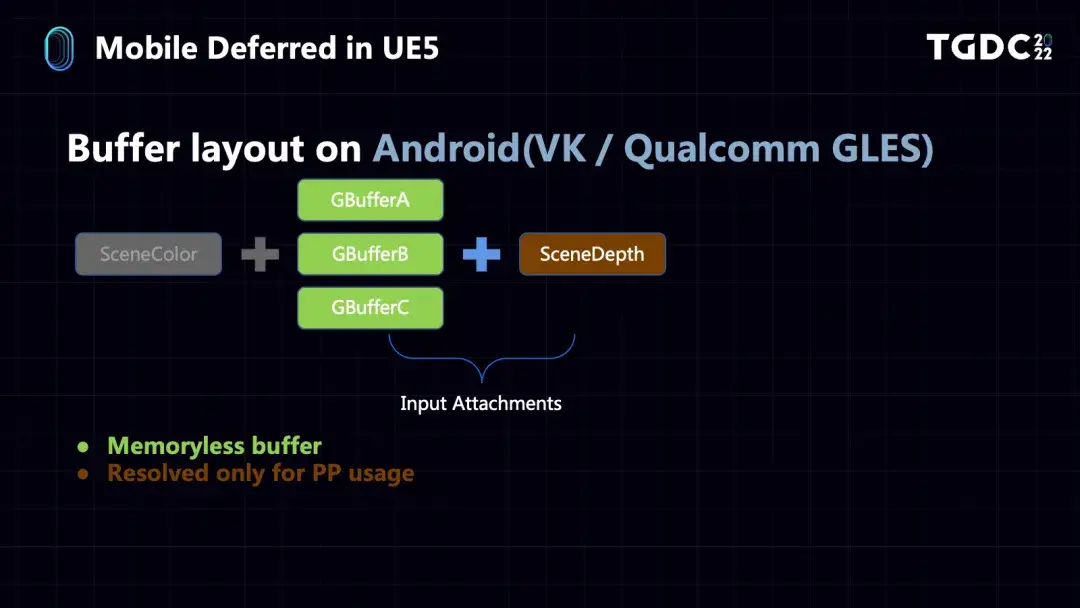
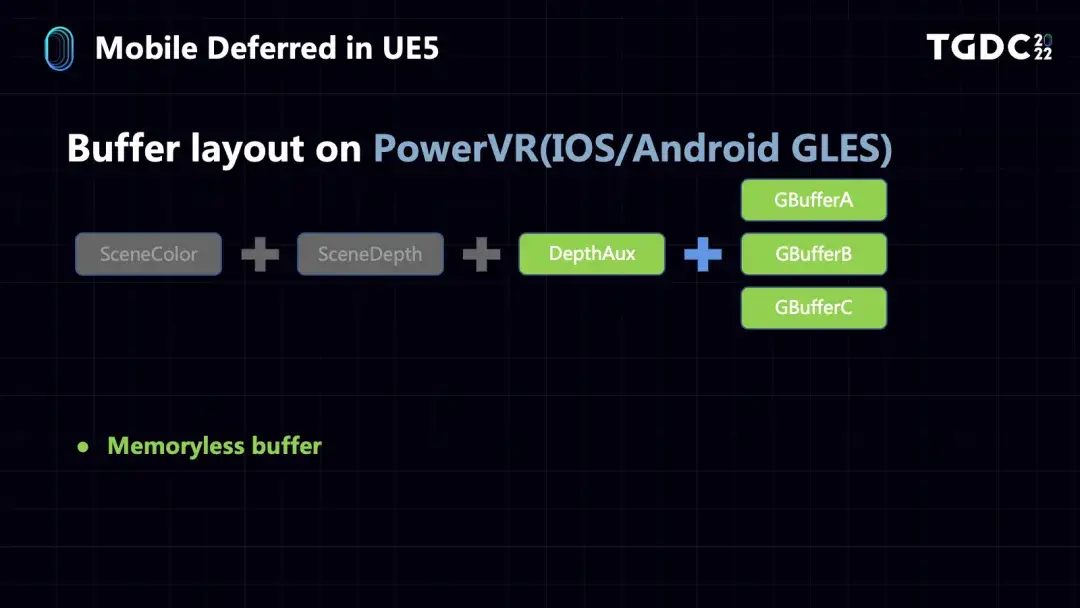
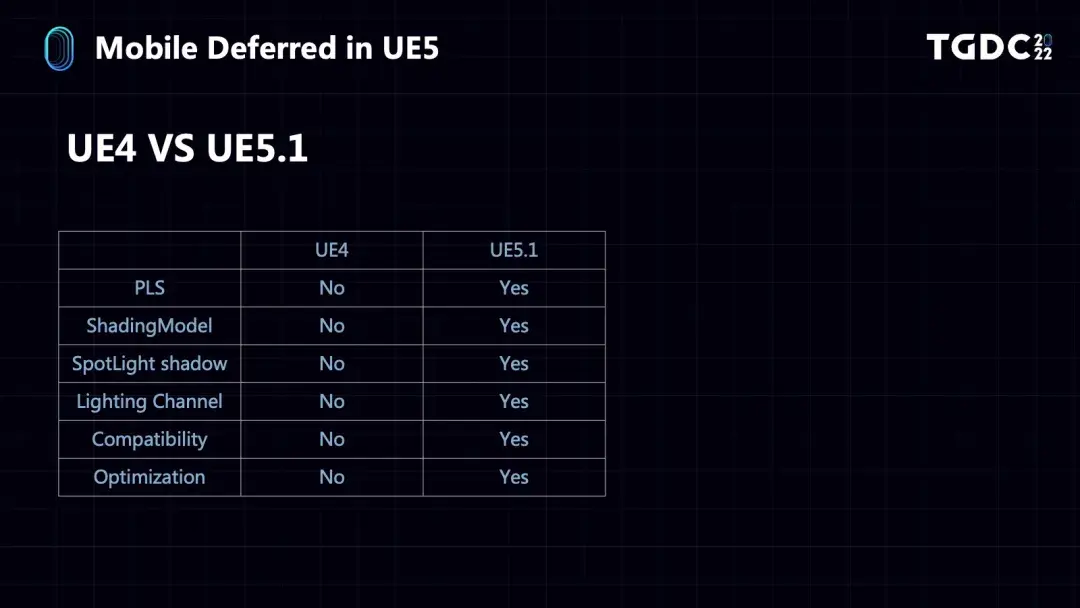
不过我们在一开始支持不同硬件平台的时候也遇到了一些问题。在对Mali设备做支持的时候,发现Mali的GPU不支持MRT的Frame Buffer Fetch,如果要支持OpenGLES,就只能使用Pixel Local Storage的技术,这其实是Arm提供的另一种MRT Frame Buffer Fetch的形式,但是Pixel Local Storage有一个很大的限制,就是它的带宽只有128bit。
然后是GBuffer的创建,在Mali设备上,如果是OpenGLES,GBuffer是在shader里用Pixel Local Storage的方式创建在Tiled Memory上的,再加上32bit的SceneColor,一共占用128bit,这也是Pixel Local Storage的一个限制。
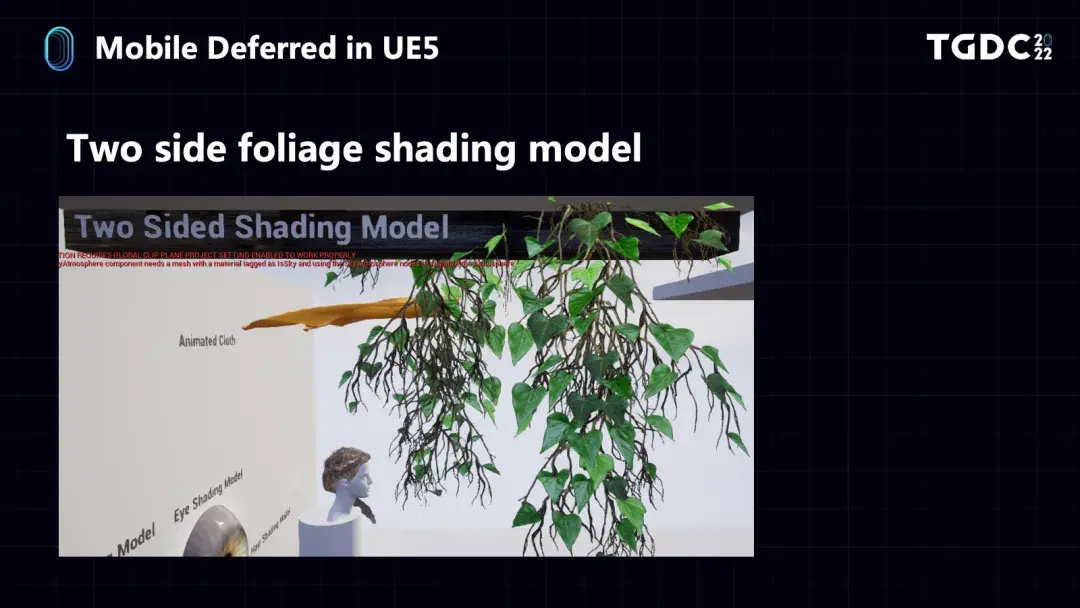
还有两个Cvar与移动端Shading Model相关,第一个是控制移动端是否支持PerPixel的Shading Model,如果支持就可以在一个材质球里有多个Shading Model效果,默认是开启的,第二个是控制在移动端上哪些Shading Model是打开的,如果没有打开就会用DefaultLit以提高效率,默认全部打开;在开启静态光照的情况下依然只支持DefaultLit,不过我们考虑添加一个选项,可以保留GBuffer数据,比如switch平台使用移动端的渲染器但它不是Tiled Based GPU,所以GBuffer数据始终会存下来,我们可以利用它去实现一些效果,比如支持Screen Space Reflection来提高switch平台上的画面品质。
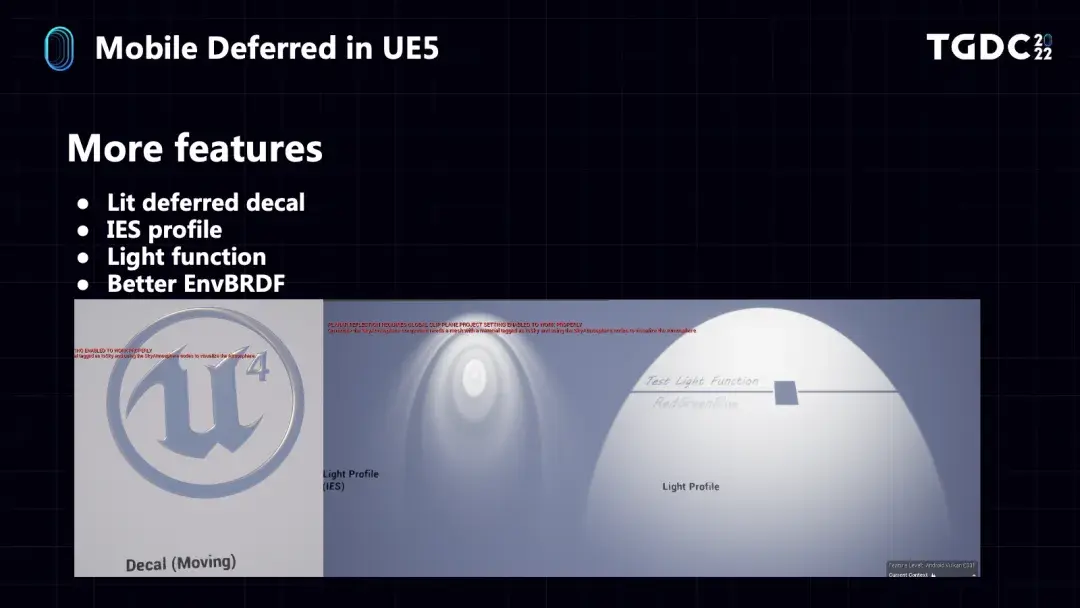
第一个是方向光的pass,可以支持方向光的Light Function,支持Clustered Local Lights、Planar Reflection以及CSM的Shadow和Distance Field Shadow。如果只有一个方向光,反射也可以在这个pass里一起计算;但如果有多个方向光,反射就需要放在一个单独的pass里去计算,以免重复计算。
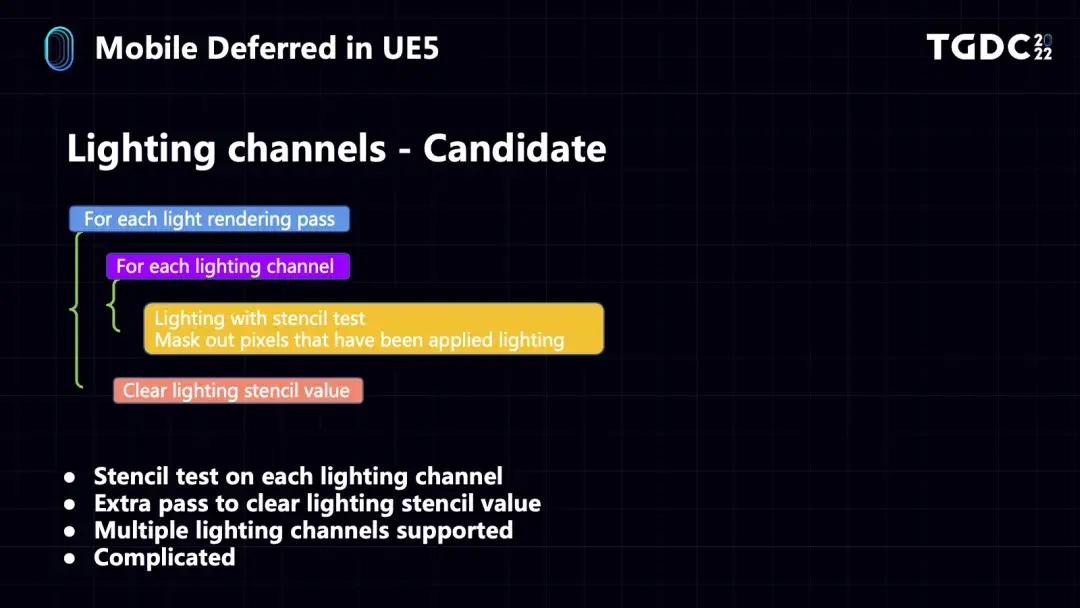
Local Light也有自己的pass,支持IES Profile、Light Function和SpotLight Shadow,Local Light是分两次绘制的,第一次在stencil标记灯光所覆盖的区域,第二次在该区域的像素里着色,以达到性能的优化。Simple Light是粒子里创建的简单光源,通常在Clustered Local Light阶段绘制,如果没有开启Clustered Local Light才会有自己的pass,此过程和Local Light的pass类似。
另一方面,我们对性能也做了一些优化,我们发现开启延迟渲染后,半透明阶段的渲染耗时比以前高,后来我们发现,是因为半透明阶段也默认开了Clustered Local Light和Clustered Reflection,对性能产生了比较明显的影响,由于我们本身对于半透明的光照和反射效果的需求并没有那么高,所以我们修改成在半透明阶段关掉这些计算,半透明的效率就和以前持平了。


 发表于 2022-9-20 08:18:32
发表于 2022-9-20 08:18:32