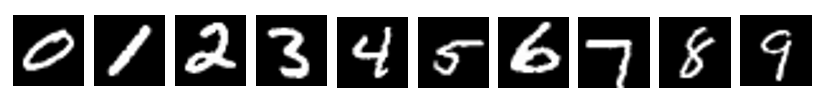立即注册
登录
搜索
前端开发
后端开发
虚幻引擎
U3D引擎
体感研发
数据库
论坛
BBS
本版
帖子
用户
麒麟软控
»
论坛
›
麒麟软控
›
后端开发
›
开始使用Poplar Triton后端
返回列表
发新帖
开始使用Poplar Triton后端
文举
文举
当前离线
积分
6
1
主题
3
帖子
6
积分
新手上路
新手上路, 积分 6, 距离下一级还需 44 积分
新手上路, 积分 6, 距离下一级还需 44 积分
积分
6
发消息
发表于 2022-11-26 17:52:51
|
显示全部楼层
随着Graphcore拟未Poplar SDK 3.0的发布,在其Poplar Triton后端库的支持下,开发人员现可在使用IPU时,利用开源的NVIDIA Triton™推理服务器。
NVIDIA Triton™推理服务器被广泛用于在生产环境中简化训练过的和微调过的模型的部署、运行和缩放。它提供针对多种类型硬件优化的云和边缘推理解决方案[1],并可以提供高吞吐和低时延。
部署使用Poplar Triton后端的模型
在本文中,我们将介绍准备环境、启动服务器、准备模型,以及向服务器发送一个样本查询的过程。
请注意,以下的示例基于使用用于IPU的PyTorch编写的模型。该工具被称为PopTorch,是PyTorch的一组扩展,使PyTorch模型能够直接在拟未硬件上运行。
PopTorch的设计旨在使您的模型能够以尽可能少的改动在IPU上运行。更多关于PopTorch的信息,请参阅拟未网站中的文档部分。
设置环境
用户需要能够获取Poplar Triton后端,以使用搭载了拟未IPU的NVIDIA Triton™推理服务器。Poplar Triton后端是Poplar SDK的一部分,您可以从拟未软件门户中进行下载。新用户可以参阅入门指南。
准备模型
部署需要一个已保存的、经过训练的模型。在这个例子中,我们将使用拟未教程库中的一个简单的mnist分类模型。
以下为训练、验证和保存模型所需的步骤,之后会被用来展示部署过程:
启用安装了PopTorch的Poplar SDK
用位于mnist教程中的要求文件运行命令:
python3 -m pip install -r requirements.txt
在“mnist_poptorch.py”脚本末尾添加一行:
inference_model.save("executable.popef")
运行带有以下指令的脚本:
python3 mnist_poptorch.py --test-batch-size 1
该操作是在IPU上使用PopTorch API训练和验证模型,并保存为executable.popef文件,供Poplar Triton后端之后使用。有关PopEF扩展的更多信息,请参阅用户指南。
模型库准备
现在,模型和其配置已经就绪,是时候准备模型库和全局后台目录了(这样做的理由请见NVIDIA Triton™推理服务器文档)。
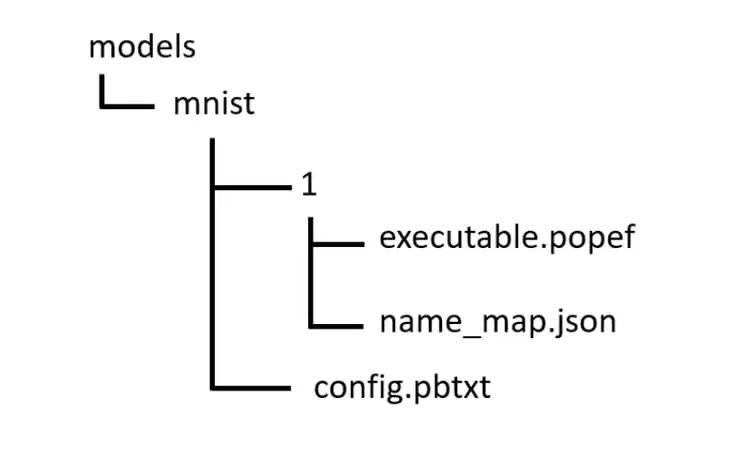
我们需要创建一个如下图所示的服务器可读的目录结构。这将是我们的模型库。刚刚生成的executable.popef文件部分非常重要。name_map.json和config.pbtxt文件的描述将在下面几段介绍。
模型的输入和输出的名称,有时候对于用户来说并不友好。有时它们还包含NVIDIA Triton™推理服务器不接受的特殊字符。name_map.json支持您重新映射这些名称。这要求您知道要重新映射的名称。为此,您可以使用工具popef_dump,它可以检查PopEF文件结构和元数据。
$ popef_dump --user-anchors executable.popef
PopEF file: executable.popef
Anchors:
Inputs (User-provided):
Name: "input":
TensorInfo: { dtype: F32, sizeInBytes: 3136, shape [1, 1, 28, 28] }
Programs: [5]
Handle: h2d_input
IsPerReplica: False
Outputs (User-provided):
Name: "softmax/Softmax:0":
TensorInfo: { dtype: F32, sizeInBytes: 40, shape [1, 10] }
Programs: [5]
Handle: anchor_d2h_softmax/Softmax:0
IsPerReplica: False
输入和输出的名称是“输入”和“softmax/Softmax:0”。该minist模型将一张手写数字的图片作为输入,并产生哪个数字代表该图片的答案。因此,digit_image和output_labels这两个名字更合适,并且不包含任何不可接受的特殊字符。下面是name_map.json文件的内容。
要在硬件上正确地运行该模型,该服务器必须具备模型和配置的具体信息。Triton推理服务器的GitHub中描述了需要这样做的原因以及各种可能性。
有许多选项可以确保模型的执行适合于我们的应用。在这种情况下,我们只想运行一个查询并得到结果,因此我们需要一个尽可能小、尽可能简单的配置。要做到这一点,我们必须指定平台和/或后端属性、max_batch_size属性以及模型的输入和输出[3]。
我们使用一个将在下一节创建的外部后端,称作“poplar”。因此,这个名字必须出现在配置文件中。
max_batch_size属性表示对于Triton可以使用的批处理类型来说,模型可以支持的最大批尺寸[4]。我们的模型是为一个批次而编译的,而且我们不打算向Triton发送多个请求,因此我们可以把这个值设置为1。
输入和输出的数据类型和大小可以通过前面提到的popef_dump工具找到。数据类型必须与popef定义的相同,但也必须以Triton服务器接受的命名法来指定。
另一个重要的问题是张量的形状。工具显示的维度的第一个值是batch_size,所以在配置文件中进行指定时应该省略这个值。如果张量被指定,则张量的名称应该从popef_dump显示的信息或文件name_map.json中改写。下面是我们将在示例中使用的配置文件的内容。
后台目录准备
模型和其配置已经就绪。现在,应该准备服务器在执行客户端应用程序发送的查询时要参考的地方了。毕竟,必须有人将模型加载到硬件上,使用客户端发送的数据运行它,并返回硬件计算的结果。Poplar Triton后端将负责这项工作。为此,我们需要创建如下所示的目录结构。
设置推理服务器
一旦您获取并启用了Poplar SDK,请下载Dockerfile,这将支持您创建一个配置了Triton推理服务器的容器。然后,请在终端运行以下命令。请注意,您在挂载目录时应能访问后端目录和模型库(-v option)。
现在,一切都已经就绪,您已经准备好启动服务器了。
执行下面的指令后,服务器将监听来自客户端应用程序的任何传入请求。
tritonserver \
--model-repository <your_path_to_models_repository> \
--backend-directory <your_path_to_backend_directory>
For example:
tritonserver \
--model-repository /mnt/host/models \
--backend-directory /mnt/host/backends
启动服务器后,监听请求的服务器的地址和端口信息将显示在终端上。我们需要该信息从客户端应用程序发送查询。
tritonserver应用程序的输出示例结束:
Started GRPCInferenceService at 0.0.0.0:8001
SessionRunThread: thread initialised
客户程序准备
请求的第一步是准备要处理的输入数据。图片可以从位于torchvision.datasets模块中的公开来源下载(我们的教程中提供了示例)。我们的mnist使用该数据集作为训练和验证步骤的数据源。下面的例子使用了这个数据集中的一些图像,您可以在此下载这些图像。每张图片的名称与图片中出现的数字相对应。这些图片:
下一步是准备一个脚本,将img文件夹中准备好的图片发送到服务器上,服务器一直在持续监听上一节中提到的地址和端口。请注意,下面的脚本假定您已经安装了几个模块:
Numpy
Pillow
Torchvision
Tritonclient
下方的脚本分为几个部分:与服务器建立连接、用预处理准备输入数据、发送和接收数据、对输出数据进行后处理、显示结果。
假设client.py包含上述脚本,在img目录下有本节开头提到的一组图片,服务器正在等待传入的请求,上述脚本的结果如下:
$ python3 client.py
Predicted digit for file &#34;0.png&#34;: 0
Predicted digit for file &#34;1.png&#34;: 1
Predicted digit for file &#34;2.png&#34;: 2
Predicted digit for file &#34;3.png&#34;: 3
Predicted digit for file &#34;4.png&#34;: 4
Predicted digit for file &#34;5.png&#34;: 5
Predicted digit for file &#34;6.png&#34;: 6
Predicted digit for file &#34;7.png&#34;: 7
Predicted digit for file &#34;8.png&#34;: 8
Predicted digit for file &#34;9.png&#34;: 9
总结
除了展示Triton后端的工作,我们也希望本文能让您感受到,IPU的使用不仅限于训练,它的可能性中还在不断扩展。这一点也反映在了《开始使用用于IPU的TensorFlow Serving》中。
在我们公开的示例中,您可以在卷积神经网络和自然语言处理系列模型中,找到配合使用NVIDIA Triton™推理服务器和IPU的示例。这两种示例的通用源代码请见utils目录。全部示例请见我们的github账户。
如果您想进一步了解我们的工具所提供的可能性,您可以参阅以下文档:
Poplar交换格式(PopEF):用于导出和导入模型的通用文件格式。
模型运行时:可以轻松加载和运行以PopEF格式存储的模型的库。供Poplar Triton后端使用。
Poplar Triton后端:如本文所简述。
用于TensorFlow 1的TensorFlow Serving和用于TensorFlow 2的TensorFlow Serving。
参考资料
[1]https://github.com/triton-inference-server
[2]https://developer.nvidia.com/nvidia-triton-inference-server
[3]https://github.com/triton-inference-server/server/blob/main/docs/user_guide/model_configuration.md#minimal-model-configuration
[4]https://github.com/triton-inference-server/server/blob/main/docs/user_guide/model_configuration.md#maximum-batch-size
查看英文blog,请至:
本篇博客作者:
Kamil Andrzejewski
上一篇:
六星云课堂:前端开发、后端、测试,哪一个适合你?
下一篇:
从月薪5K到年薪40W+,详谈我的C/C++ 后端开发之路!
回复
举报
使用道具
分享
与我彤在
与我彤在
当前离线
积分
7
1
主题
4
帖子
7
积分
新手上路
新手上路, 积分 7, 距离下一级还需 43 积分
新手上路, 积分 7, 距离下一级还需 43 积分
积分
7
发消息
发表于
昨天 20:51
|
显示全部楼层
啥玩应呀
回复
举报
使用道具
返回列表
发新帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
快速回复
返回顶部
返回列表
 发表于 2022-11-26 17:52:51
|
显示全部楼层
发表于 2022-11-26 17:52:51
|
显示全部楼层